Transactions are the core feature of MySQL database, and one of the reasons why engineers choose it as a datastore for their applications.
But have you ever wondered what happens during a transaction? How is the consistency maintained? What happens if a concurrent read occurs during a transaction?
In this article, we will discuss what happens when a transaction is executed.
People who are not members can read this article here: link

Before diving deeper, you should be aware of some common terms that will be used repeatedly throughout this article.
- Buffer Pool: This is an in-memory storage that keeps the data, and whenever there is a read request, the first lookup happens here before any fallback.
- Redo Logs: This is a write-ahead log (WAL) in MySQL. It is used for maintaining the durability of the database.
- Undo Logs: This keeps the old version of the data, helps in maintaining consistency using the MVCC (Multi-Version Concurrency Control) protocol.
- Redo Logs Buffer: This is an in-memory storage to keep the redo logs data.
- Undo Logs Buffer: This is an in-memory storage to keep the undo logs data.
. . .
Imagine a transaction is going on where data has to be inserted, and the state of the data record is getting updated. Simultaneously, another service request to read the value of the same row, which is supposed to be completed, but has not yet been completed.
I know, you must be thinking that the simple answer is a single query outside the transaction will get an empty response. But how?
To understand this, let's walk through with an example of a transaction that has the following steps:
- Transaction Begin
- Insert a row in the user table (id: 1, name: Rony, state: CREATED)
- Update the state of the user having uid: 1 to INPROGRESS (id: 1, name: Rony, state: INPROGRESS)
- Read the data of the user having uid:1 (id:1, name: Rony, state: INPROGRESS)
- Again, update the state of the user having uid: 1 to COMPLETED (id: 1, name: Rony, state: COMPLETED)
- Transaction End
Let’s go step by step in the process….
Step 1: Transaction begins
When a transaction begins, the database allocates a transaction ID (TID), sets up an in-memory structure to keep track of transaction metadata (modified pages for the buffer pool, undo log entries, and acquired locks). Nothing is written on the undo or redo log buffer yet, but to control MVCC visibility and guarantee appropriate crash recovery, the transaction is additionally added to the system-wide list.
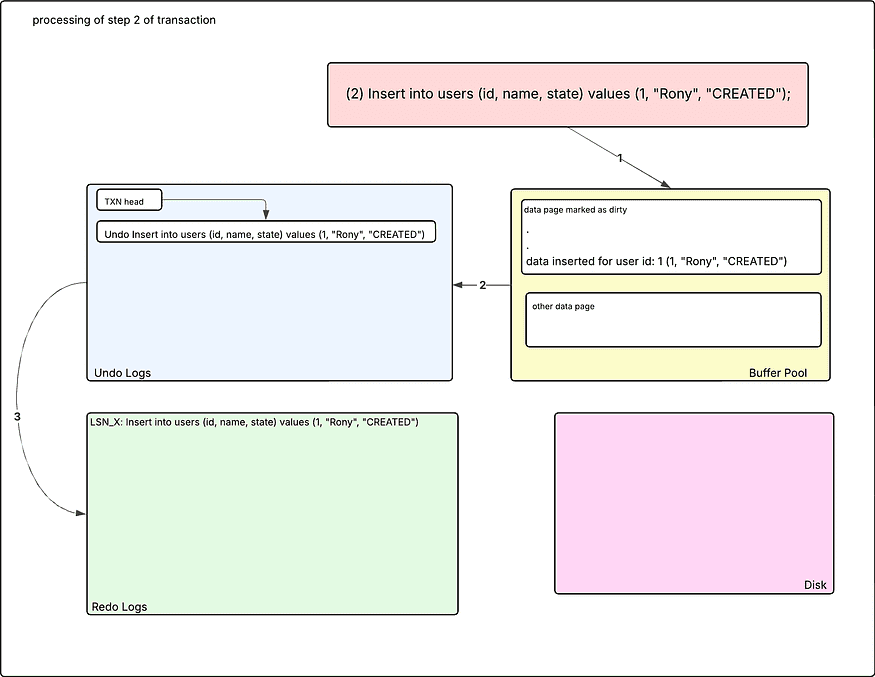
Step 2: Insert a row in the user table
This is the first step of database operation, where data insertion will happen. MySQL engine first checks if data is present in the database for the primary key. If yes, then the call fails at the same time; if not, then it will first find the data page in the buffer pool if not present in the buffer pool, then it first fetches from the disk and inserts the row into that data page, and then marks it as dirty.
Datapage marked as dirty indicates that the data present in the data page is modified but not yet saved to disk.
Before the insertion is complete, the entry is created in the undo log buffer to keep a copy of the previous state, which helps in rollback and consistent reads for the other transactions. The entry gets linked to the transaction segment in the undo log buffer.
Along with it, an entry is created in the redo log as well for the durability of the data. And then a lock is acquired.
Till this point, all the changes are in memory; no changes have been saved to disk.
 created by ankit
created by ankit
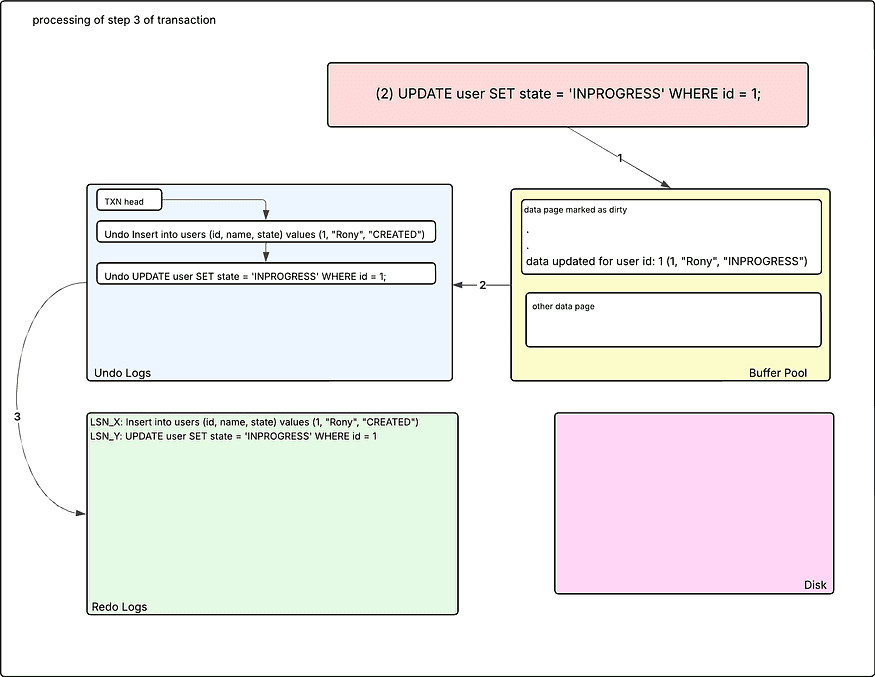
Step 3: Update the state of the user having uid: 1 to INPROGRESS
Now, an UPDATE is invoked. The engine looks for the data page in the buffer pool, which contains the data for the given ID. If the datapage is dirty and the changes were done by the same transaction, then it proceeds further by updating the data. In this case, the state was updated to INPROGRESS.
Also, the previous state of the data is added to the undo log buffer as a link to the transactions segment, and is also added to the redo logs buffer.
 created by ankit
created by ankit
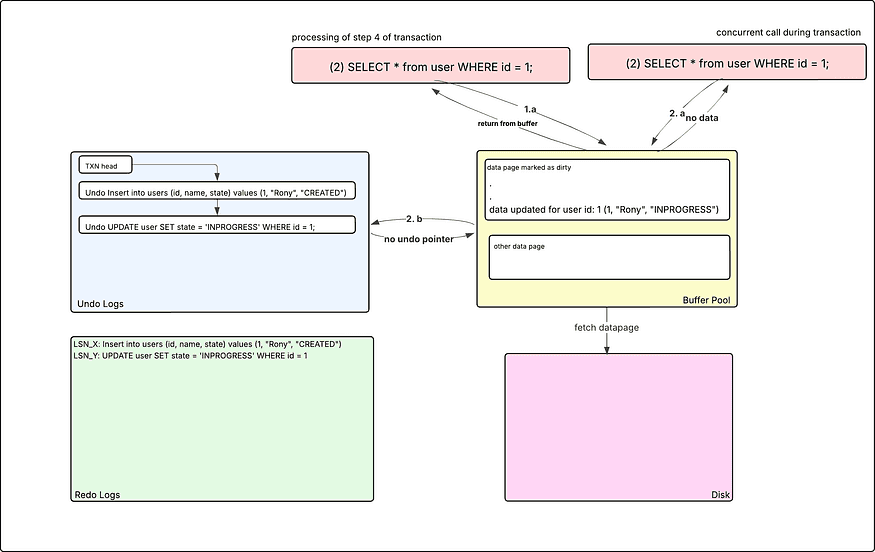
Step 4: Read the data of the user having uid: 1
When the select query gets invoked, it follows the same process, first checking in the buffer pool if the data page is present or not, for the requested ID; if not, then it loads from the disk. If the datapage present in the buffer pool is marked as dirty and uncommitted, then MVCC metadata helps in retrieving the correct data for the transaction.
There can be two scenarios. Let’s discuss one by one.
- In the first case, if the transaction ID is the same that marks the data page dirty and the transaction query for the data, then it returns the same data.
- Second one, if the transaction ID is different, that marks the data page dirty, in this case, it looks into the latest committed version from the undo log pointer and returns the data, if present.
In the current case, if a different transaction invokes the lookup for the user ID: 1, then no data will be returned as there is no undo log pointer for the stable version of the row ID: 1.
 created by ankit
created by ankit
Step 5: Update the state of the user having uid: 1 to COMPLETED
This step will remain identical to Step 3. The data is updated to the buffer pool, and entries are created in the redo/undo buffer log accordingly.
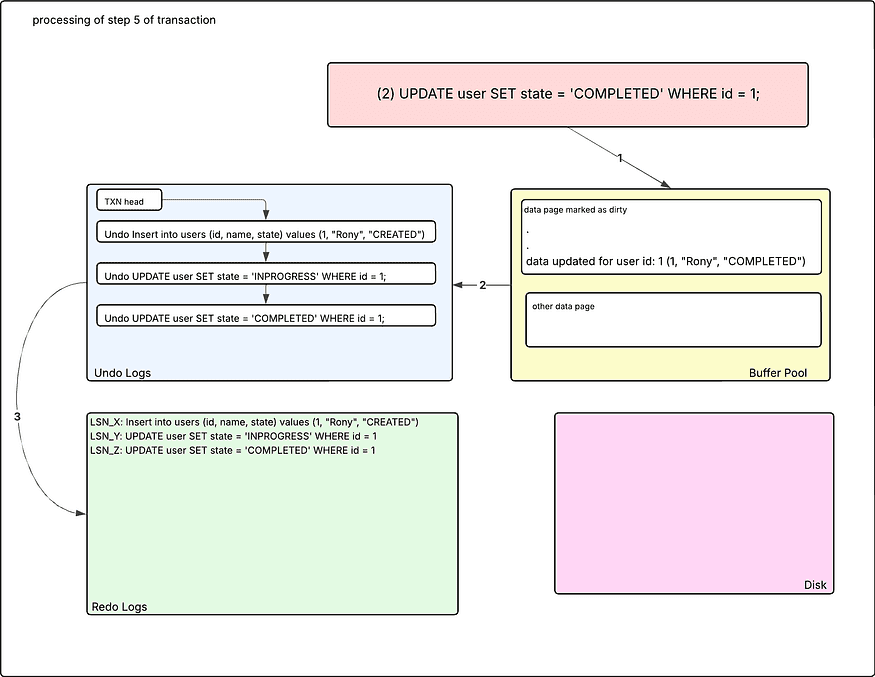 created by ankit
created by ankit
Step 6: Commit Transaction
Now comes the last step: COMMIT. When all of the statements in a transaction are executed, this step gets invoked. The redo logs buffer (in-memory) gets flushed to the redo logs (disk), and the transaction is marked as committed in the transaction table. The datapage still remains dirty and flushed to the disk lazily.
This is how the transaction gets successfully executed.
Wait, but what happens if at any point the transaction fails and needs to be rolled back?
In that case, the DB engine first rolls back the changes from the undo log associated with the transaction to its original state. For the data changes in the data page of the buffer pool, the engine ensures that the changes are undone to maintain data consistency.
During crash recovery, the redo logs are executed and roll back the changes of uncommitted transactions from the undo log.
. . .
Conclusion
In this article, we discussed the execution of MySQL transactions. How buffer pool, redo, and undo log work, which helps us in understanding the reasoning of concurrency, consistency and data recovery in it.
You can think of different scenarios and apply these insights to understand how the MySQL engine handles them.
If you found this article helpful, then please clap, share, and follow for more insights on tech and distributed systems!