You have 100 tasks, some depend on others, and some fail midway and your interviewer says:
Execute these tasks as fast as possible without breaking the dependency order
This simple requirement quickly turns into a DAG-based task executor problem, commonly asked in companies like Uber, Amazon, PhonePe, etc.
There are different variations of this problem. Today, I will discuss one of the types.
Problem statement: There is a list of tasks, some of which are dependent on other tasks.
- The dependent tasks form a directed acyclic graph.
- A task execution starts only if all the dependent tasks are completed.
- In case any of the dependent tasks fail, then the primary task will also fail.
- All tasks should be executed as fast as possible in parallel or serially.
Before reading further, I highly suggest that you give 30 min to solve this question and then check the approach.
Understanding the problem statement
In this problem, we have been given a list of tasks.
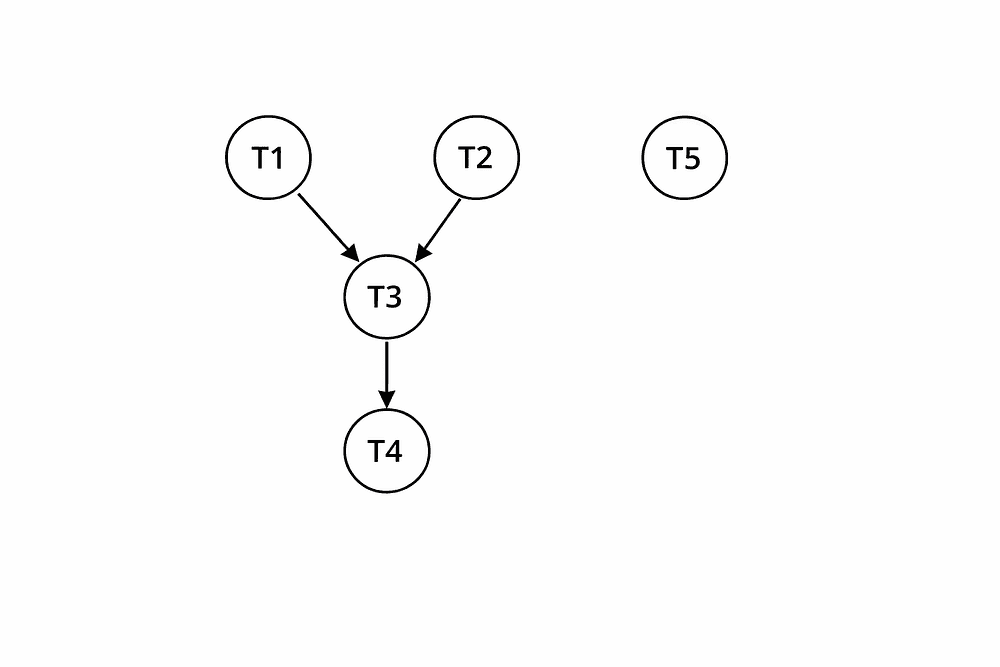
let say: [T1, T2, T3, T4, T5]
Some of them are dependent on other tasks:
T1 => No dependenciesT2 => No dependenciesT3 => [T1, T2]T4 => [T3]T5 => No dependencies
Given that the tasks are dependent on each other, this can be converted into a directed graph. For the above case, the graph looks like this:
The first approach
The first approach that came to my mind was to create a dependency matrix, perform a topological sort, and execute the tasks from left to right.
But there is a problem with this approach: the speed is not guaranteed. A dependent task could block the independent tasks that can be executed before it.
Topo Sort for the given sample: T1, T2, T3, T4, T5.
Here, T3 can block the execution of T5.
The order of independent tasks execution won’t matter, as speed matters more than priority, according to the question.
To support this statement, let’s consider that we have a thread pool executor of 2 threads, which can execute two tasks in parallel.
Initially, T1 and T2 got executed, and T1 took x seconds while T2 took x+y seconds. Instead of waiting y seconds for T2 to complete and for T3 to start execution, T5 can be executed. But this approach has limitations.
The Second approach
Given that the execution of a task can be dependent on others, there must be a degree of dependency associated with it. In a graphical representation, that can be clearly seen as an indegree.
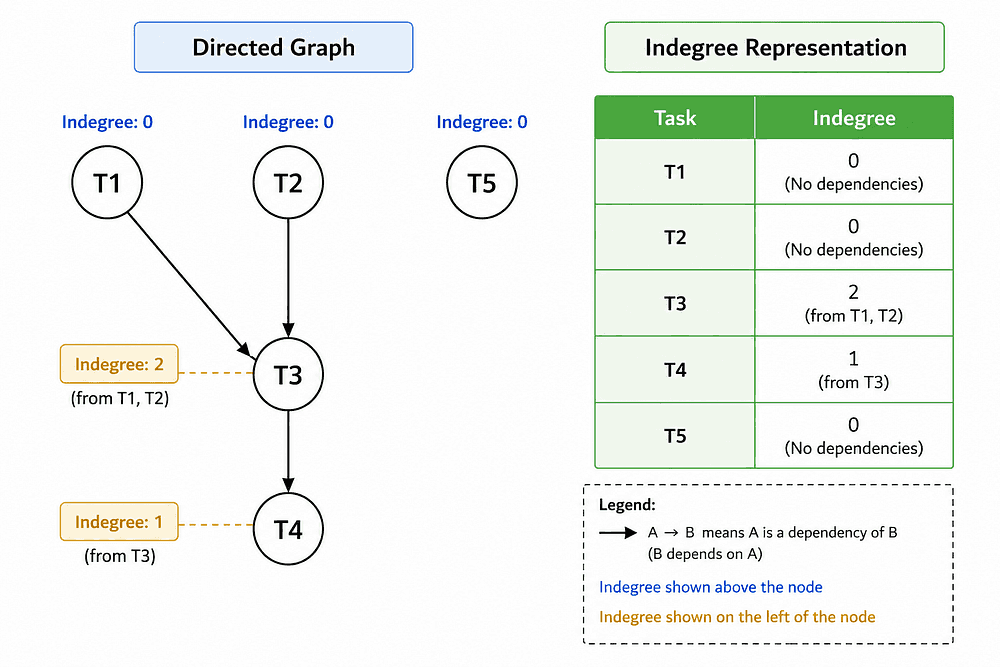
What if I reduce the indegree as soon as the dependent task is completed, poll the tasks whose indegree becomes zero, and execute them as soon as a thread is available? This looks like a much better approach.
For this, I will need to maintain an inverted dependency graph so that if a dependent task is completed, it notifies all the tasks dependent on it.
T1 : T3T2 : T3T3 : T4T4 : NoneT5 : None
With this approach, iterative indegree count won’t be required for T4 as it will be notified only if T3 is completed, which itself is dependent on the other two tasks (T1 & T2).
The final degree mapping will look like:
T1 : 0T2 : 0T5 : 0T3 : 2T4 : 1
A scheduler with two threads will pick the T1 & T2 tasks at first. As soon as either task is completed, the thread will pick the next task with 0 indegree. But there is a risk of race conditions.
For example:
T1&T2were completed simultaneously- Both threads tried to reduce the indegree concurrently
- Count reduced inconsistently
We can solve it using locks, synchronised blocks, or an atomic counter in Java. But does Java provide any better abstraction?
The Third approach: Java CompletableFuture
Instead of maintaining execution states, polling queues, and thread coordination, we can create each task as a future, and its execution will depend on the completion of other futures.
This is how a DAG will get converted into an async execution graph.
Execution flow :
T1— async executionT2— async executionT5— async executionT3—CompletableFuture.allOf(T1_Future, T2_Future)T4—CompletableFuture.allOf(T3_Future)
T3 execution will depend on T1 & T2, and similarly for T4.
High-Level Design
Task Class :
public class Task {
private final String taskId;
@Builder.Default
private CompletableFuture<String> future = new CompletableFuture<>();
@Builder.Default
private List<String> dependencies = new ArrayList<>();
}We can maintain :
private final ConcurrentHashMap<String, Task> taskMap = new ConcurrentHashMap<>();
ExecutorService executorService = Executors.newFixedThreadPool(10);DAG Construction:
for (Task task: tasksMap.values()){
Set<CompletableFuture<String>> dependentFutures = new HashSet<>();
for (String dependentId: task.getDependencies()){
dependentFutures.add(tasksMap.get(dependentId).getFuture());
}
CompletableFuture
.allOf(dependentFutures.toArray(new CompletableFuture[0]))
.thenRunAsync(()-> execute(task), executorService);
}Complete execution:
CompletableFuture.allOf(tasksMap
.values()
.stream()
.map(Task::getFuture)
.toArray(CompletableFuture[]::new)
).join();CompletableFuture also supports failure propagation; if T2 fails, then T3 & T4 will also fail.
This is how we can create a task scheduler with:
- Maximum parallelism
- Correct dependency ordering
- Automatic failure propagation
- Minimal synchronization complexity
Conclusion
In this article, we discussed how to create a task scheduler. I hope this article will help you in preparing for a machine coding interview.
If you found this helpful, please clap, share, and follow me for more insights on tech and distributed systems!